Look-Ahead Selective Plasticity for Continual Learning
NeurIPS (UniReps Workshop) · 2024
We propose a look-ahead selective plasticity mechanism that combines contrastive learning
and distillation to reduce catastrophic forgetting in continual visual learning. By valuing
features that both preserve past knowledge and transfer to new tasks, the method achieves
state-of-the-art performance on CIFAR-10 and TinyImageNet.
Continual learning systems often suffer from catastrophic forgetting due to uniform
parameter plasticity across tasks. In contrast, our method models learning as a sequence of
events and introduces a look-ahead evaluation step to guide plasticity decisions at task
transitions.
Many existing approaches estimate parameter importance solely based on past tasks, leading
to overly stable solutions that gradually lose the ability to learn. Our key motivation is
that features valuable for continual learning should be assessed not only by what they
retain, but also by how well they transfer to future tasks.
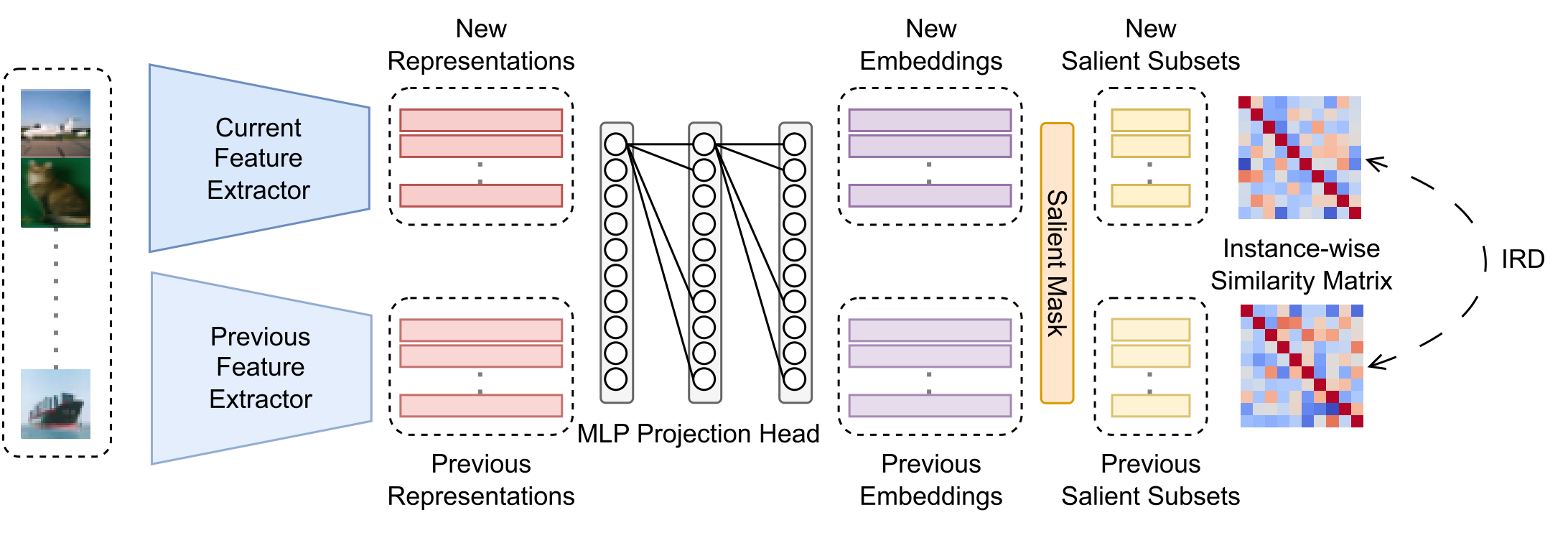
To capture this, we introduce a look-ahead selective plasticity mechanism that uses a small
number of samples from a new task to estimate the transferability of learned features. At
the level of embedding neurons, we evaluate performance jointly on data from previous tasks
and the first batch of the new task. Neurons that preserve performance under this joint
evaluation are treated as transferable and selectively protected, while the rest of the
network remains plastic.
This process is implemented through selective plasticity, using a distillation loss applied
to a subset of embeddings, and gradient modulation, which dampens updates to salient
parameters that contribute to both transfer and past-task performance. This design allows
the model to adapt to new tasks with a larger set of free parameters, while preserving
transferable features learned earlier.
Experiments on CIFAR-10 and TinyImageNet show higher average accuracy, reduced forgetting,
and improved forward transfer compared to regularization- and distillation-based baselines,
while maintaining competitive performance on new tasks.